Идеи разделения на модули и микросервисы
В наших скринкастах скринкасты мы дошли до программирования доменной модели большого проекта аукциона. Имеющееся подробное задание теперь нужно реализовать в коде. Разобраться с доменными контекстами и пройтись по пользовательским сценариям, чтобы выстроить удобную архитектуру модульного проекта. Это мы рассмотрим в следующих скринкастах.
Но помимо аукциона нам будет крайне полезно более ёмко рассмотреть примеры из других предметных областей. Как растёт и развивается бизнес. Как это отражается в программном коде при его автоматизации и какие подходы в разработке нам могут быть полезны. Для этого мы проведём большой обобщающий стрим про декомпозицию кода на модули и микросервисы:
Для участников также будет полезен мой доклад на смежную тему:
Вертикальное разделение кода, тестов и конфигов
На стриме как раз дополним этот подход расcмотрением внутренностей этих модулей и способами взаимодействия между ними.
UPD: Стрим успешно проведён
Начали с примера эволюции при автоматизации бизнеса завода железобетонных иделий. Заодно обсудили продажу бетона с ароматом клубники для VIP-клиентов. Рассмотрели появление сервисной архитектуры при интеграции готовых сервисов каталога, блога, заказа, CRM, оплаты, склада и доставки чужими сервисами и своими водителями:
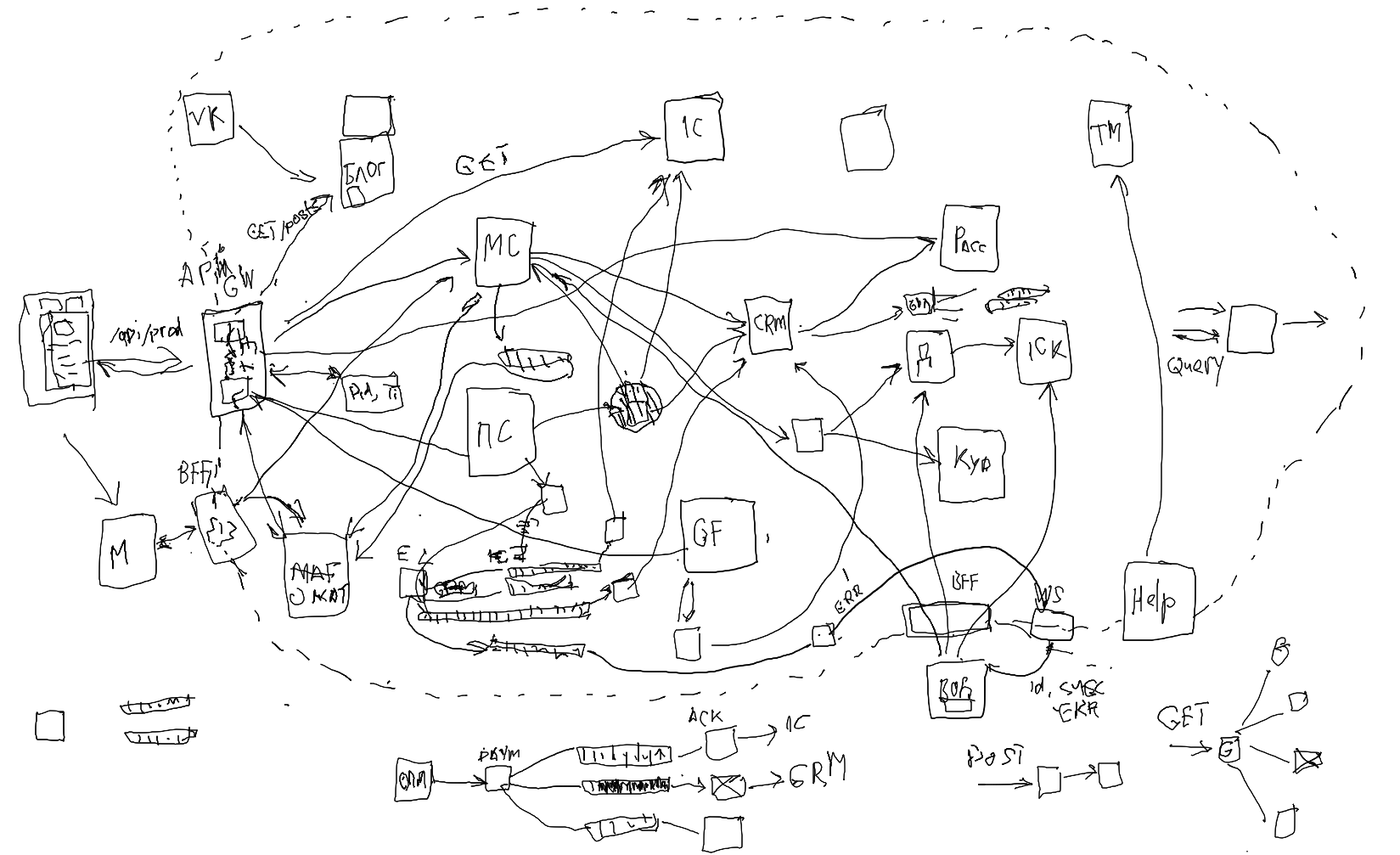
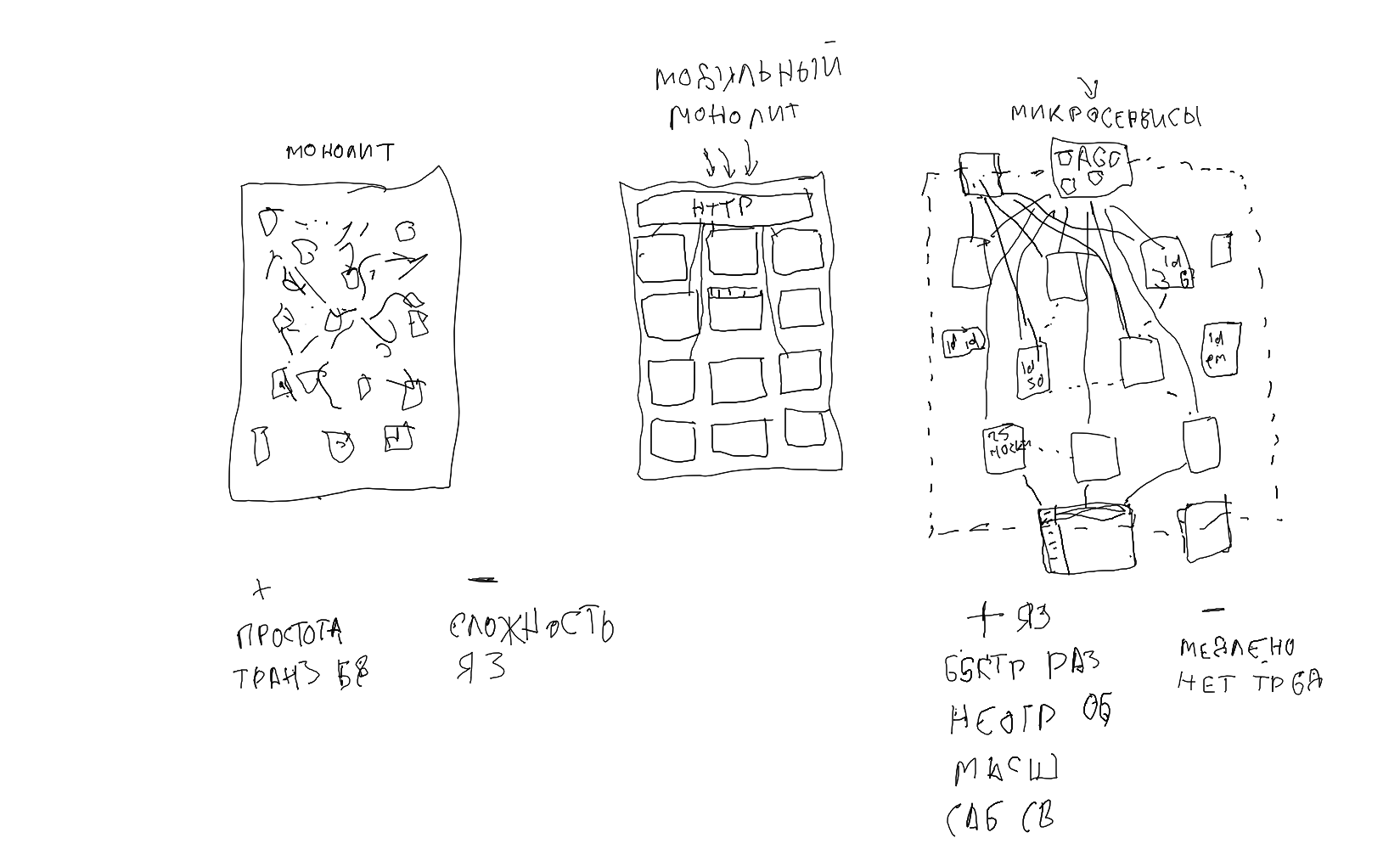
Потом плавно от системы готовых сервисов перешли к модульной и микросервисной архитектурам. Рассмотрели плюсы и минусы подходов вначале и в долгосрочной перспективе:
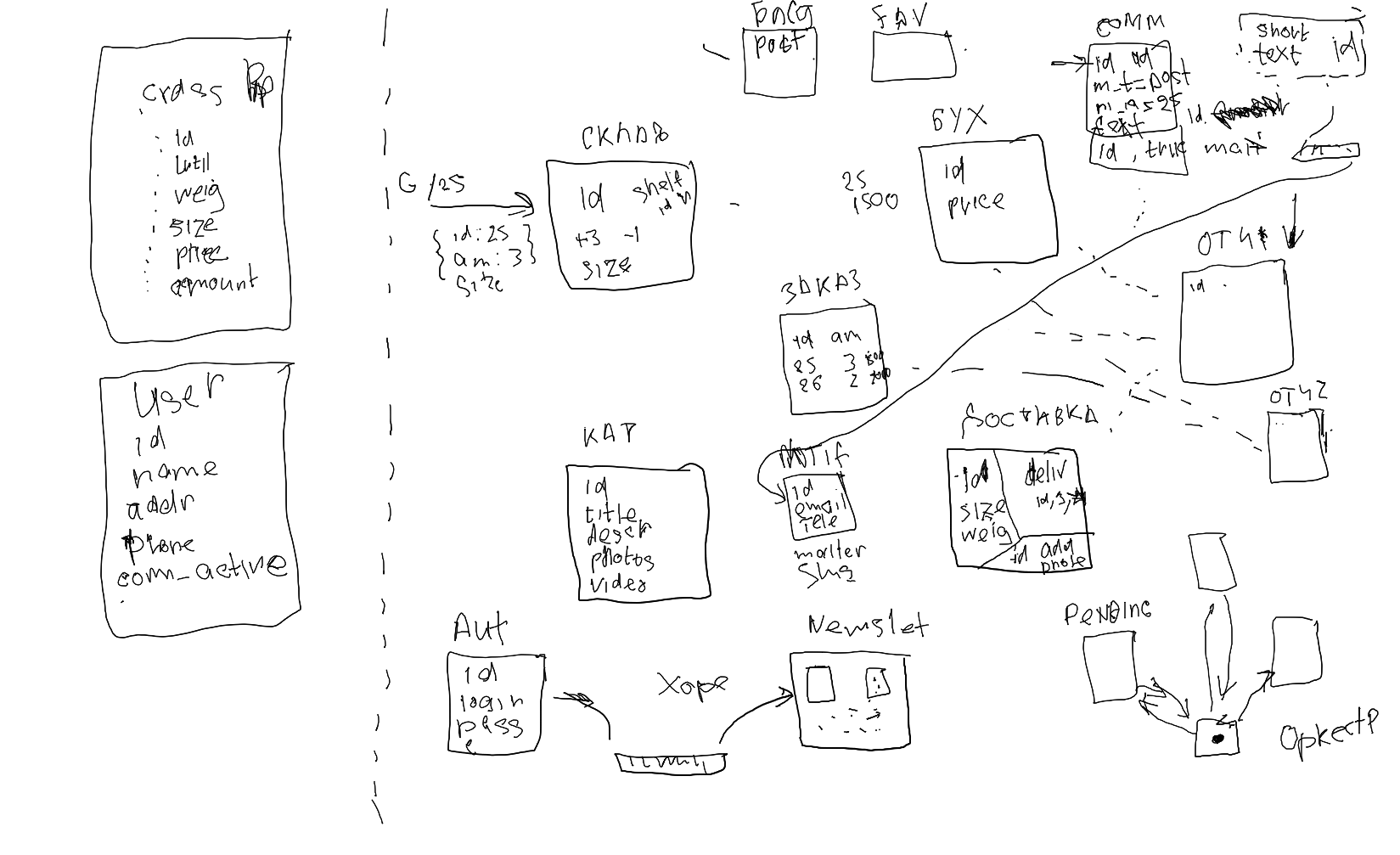
И в итоге организовали систему так, чтобы всё было максимально автоматизировано и понятно. Много внимания уделили минимизации связей между модулями или микросервисами. Тому, как более успешно определять контексты и раскладывать данные так, чтобы сервисам не приходилось ходить друг к другу:
Что в итоге получилось в видеозаписи:
- 00:00:00 - Проверка связи
- 00:04:18 - Что сегодня будет
- 00:14:58 - Использование бизнесом готовых сервисов
- 00:31:50 - От ручной работы к интеграция через API
- 00:44:29 - Написание своих сервисов
- 00:48:00 - Перекомпоновка данных
- 00:53:54 - Работа с сервисами без API
- 00:56:38 - А давай всё перепишем...
- 00:58:56 - Рост проекта и новые направления
- 01:02:08 - Сервисная архитектура
- 01:07:17 - API Gateway или Backend For Frontend
- 01:14:46 - Проблема надёжности для Query и Command
- 01:20:06 - Взаимодействие через очереди сообщений
- 01:26:18 - Продвинутые брокеры очередей
- 01:40:50 - Надёжная очередь и Outbox Pattern
- 01:45:40 - Компенсация операций
- 01:46:53 - Уведомление фронтенда о результатах операций
- 01:50:35 - Перерыв
- 02:09:28 - Ответы на вопросы
- 02:34:31 - Монолит, модули и микросервисы
- 03:04:25 - Ответы на вопросы и про DDD
- 03:13:39 - Единый язык и ограниченные контексты
- 03:21:05 - Разделение данных по кнотекстам
- 03:41:02 - Как выглядит в программном коде
- 03:46:00 - Формат именования слушателей
- 03:49:30 - Пример слабосвязанных модулей
- 04:05:18 - Почему не использовать Repository для выборок
- 04:15:18 - Application Side Joins
- 04:28:38 - Отдельные конфигурации для модулей
- 04:33:13 - Минимизация хождения за данными
- 04:41:53 - Дублирование и DRY
- 04:46:27 - Авторизация через роли и разрешения RBAC
- 04:58:22 - Слабосвязанные модули и сервисы
- 05:00:30 - Саги через хореографию или оркестрацию
- 05:05:41 - Вынесение модуля в микросервис
- 05:07:33 - Вывод отчётов и сложных выборок
- 05:13:49 - Специализация на людей в команде
- 05:16:53 - Система уведомлений
- 05:22:22 - Промежуточный вывод
- 05:25:46 - Ответы на вопросы
- 05:30:22 - Многошаговый процесс в распределённой системе
- 05:35:31 - Ответы на вопросы
- 06:28:58 - Тишина и покой
А в следующем стриме от идей перейдём к практикам разработки новых проектов и внедрения в существующие. А потом реализуем в программном коде паттерн Transactional Outbox для надёжной отправки и доставки событий через RabbitMQ.
Оплатить можно самому российской или иностранной картой или попросить работодателя оплатить от имени компании.
Для скидки можете сначала оформить в кабинете безлимитную подписку на наши полезные скринкасты.
А потом или сейчас приобрести записи стрима можно там же в кабинете или здесь:

Запись и может какие-то материалы остануться? (код..., может еще что-то)
Да, всё останется для участников
Добрый вечер, а сколько по времени будет стрим? Спасибо
Ориентируюсь на 4..5 часов с небольшими перерывами и ответами на вопросы
Значит, минимум на 8ч :)
Никита бывалый))
Получилось всего 6ч :)
Дмитрий, а можно будет чуть позже приобрести записи и материалы стрима? В текущий момент для меня изучение темы микросервисов рано, но попозже планирую погрузиться в эту тему.
Да, можно потом, но по возросшей цене.
Очень нужна информация про kubernetes. Будет ли в планах?
Будет в скринкастах.
Дмитрий, а подскажите в 22:00 по мск? или это по моему времени уже отображается?
В 18:00 по московскому. Это уже отображается по местному.
супер, значит тогда получится поприсутствовать. А может как нибудь помечать время, а то вдруг может кто еще не понял) если что вот так у меня отображается https://i.imgur.com/Y9FUICq.png
Пометил
я думаю, что будут еще косяки :) К примеру, у меня на компьютере региональные установки страны в которой я постояннно проживаю, или просто удобнее чтоб всё было на английском (все форматы), я на несколько месяцев уехал в другую страну, что ж мне установки в компе менять? Если б я случайно не заметил пост Владимира, то пришел бы в 17-00, а не в 16-00.
Урвал за 1700
Здравствуйте! вебинар рассчитан на тех кто уже работал с микро-сервисами? Или подойдет для тех, кто только начинает изучать эту тему?
Для всех будет интересен.
Дмитрий. Хотелось бы услышать для каких проектов уже стоит задумываться об использовании такой архитектуры. Только не ограничиваясь словами "большой и маленький", если большой то сколько и чего . Спасибо.
Если я куплю, то я автоматом куплю и подписку ?
Нет, подписка приобретается отдельно в кабинете.
Как обычно с задержкой) но ради такого стоит подождать))
Произошли технические шоколадки) Все будет ок
Стрим удался, хоть и понервничали в начале. Спасибо зрителям за интересную компанию и вопросы!
у меня ссылка так и не появилась. как можно получиь ссылку на запись?
Попробуйте обновить страницу
Спасибо за стрим! Всё прошло хорошо, было интересно и полезно)
Добрый день, спасибо за стрим! А можете подсказать как такое разделение на модульный монолит произвести для модуля Корзины. Так как ей все время нужны данные о пользователе, товаре, остатках, ценах, которые могут быстро менять. Плюс в ней могут быть какие-то системы скидок. То как в контроллере должен обрабатывать запрос содержимого корзины, добавление товара. Как внутри модуля корзины мы будем получать актуальные данные? Думал через подписчиков, но, например, цены в разных городах могут быть разные. И тут пользователь переключает город и соответственно все события изменения цен для нового города он ранее пропускал и уже нет возможности их актуализировать. В итоге у себя в реализацию пришёл к тому, что модуль Корзины сам ходит в кучи апи других модулей. Может есть более хитрые варианты?
Хочу поделиться своим мнением, пока нет ответа Дмитрия.
В целом по этой теме есть интересный доклад, как раз рассматривается пример с корзиной: https://youtu.be/MotE7e30jGM
Как и ответили выше, в простой корзине достаточно хранить только id товара и добавленное количество. А всё цены для отображения на сайте подтягивать на лету в момент запроса.
Обычно цены товаров нужно фиксировать только при заказе. В корзину их копировать нет смысла.
Изначальные цены могут отличаться от фактических. Например при вводе промокода, скидку по часам и т.д., тогда необходимо хранить в корзине новые цены. Далее можно формировать отчёты с ценами изначальными и после применения скидок.
Промокод применяется при оформлении заказа, а не при добавлении его в корзину. Человек может вернуться в корзину через месяц, когда ваш промокод уже не действителен.
Тоже самое касается часов. Положил товар в корзину в один час, а оформил на следующий день в другой. Если вы цену положите в корзину с учетом часа, то вам придётся настроить крон, который будет пересчитывать каждый час.
Отчет формируется по фактическим заказам, а не тем, которые могут никогда не стать заказом. При таком подходе отчёт будет недостоверный.
Для меня стим полезный, спасибо.
Вы показали как храните конфиги модулей не в общем каталоге /config, а индивидуально в каждом модуле. Они при этом все равно парсятя ВСЕ при каждом запросе (тем же laminas-config-aggregator)? Или есть способ парсить их только тогда, когда используется данный модуль? Ну, чтобы снизить время запроса в большом проекте..
В этом компоненте возможно включить кэширование готового массива в файл, передав файл:
и в продакшеновской конфигурации включив опцию:
Это будет экспортировать весь общий массив в файл, сэкономив нам время на загрузку и merge всех массивов.
Но любое такое кеширование не позволяет экспортировать анонимные функции вроде наших фабрик:
Чтобы это заработало нам нужно будет вынести эти фабрики в отдельные классы:
и в конфигурации указать строками имена этих классов:
Тогда у нас будет кэшируемая конфигурация в виде массива из строковых имён классов без анонимок.
Вот это развёрнутый ответ, каким он должен быть! Спасибо!
Я его понял так:
Загружать конфиги по отдельности on-demand нельзя, но зато можно все кешировать в случае laminos-aggregator.
Да, так.
Некоторые компоненты поддерживают кэширование. Но его можно сделать и вручную вроде:
собрав массив и записав его в файл через
var_export.Либо есть альтернативный вариант с запуском проекта в RoadRunner, где конфигурацию и создание контейнера можно произвести всего один раз при запуске сервера, а не на каждый запрос. Тогда кэширование и загрузка по требованию не пригодятся.
Но тогда нужно будет программировать все сервисы без изменяемого состояния вроде
$translator->setLang(...), чтобы второй посетитель случайно не увидел ответ на языке, сохранёным в переводчике от первого.Очень крутой стрим, много полезной и новой для меня информации. Хотелось бы еще только больше практической части посмотреть как организовать всю эту свистопляску с джобами и очередями. Там где синхронные подписки — все понятно: есть событие, есть слушатель. А вот с асинхронностью и очередями как? Посмотреть бы как реализовывать это в коде, как все разложить. Спасибо!
++ тоже хотел бы посмотреть на такое
В следующем стриме про практики разделения как раз полностью реализовали работу с очередями по паттерну Transactional Outbox для хранения и передачи событий.
Спасибо за стрим, очень много полезной инфы было!
Возникло пару вопросов по теме. У меня по крону дублируются данные нескольких сущностей с другого сервера, которые нужны исключительно для вывода при помощи фетчера на фронтенд. (в реалтайме делать любые запросы с первого сервера на второй очень долго)
К примеру, такая сущность Product. По сути, чтобы записать ее в БД, мне не нужна доктрина, поскольку никаких манипуляций с данными производить не нужно.
По этому для записи в БД есть вариант сделать по аналогии с фетчером – WriteModel/ProductWriter. Или же создать ProductRepository и там делать запись, но не через доктрину, а голым sql. но тогда возникнет путаница что репозиторий обычно для доменных сущностей использовался, а тут исключение. как лучше поступить?
Также не могу определиться что делать с entity. Если не создавать то не будет миграции.. А если создам, то надо как-то закрыть ее от использования в коде программистом.
Если с чужого сервера, то да, придётся забирать данные к себе по крону.
Да, для такой синхронизации ничего не нужно. Можно сделать отдельный модуль или сервис вроде ProductsSync.
Можно сущность пометить аннотацией
@internalи поместить в папку с сервисом. Тогда Psalm не разрешит вызывать её из других мест.6.5 часов.. таймкоды бы очень облегчили жизнь!
С организацией доменных событий я уже не первый раз себе вопрос задаю как лучше и сам пока не пришел к одному мнению.
Вот у вас на 3.44.43 -
UserSignedUpсобытие вAuthмодуле, аSubscribeOnAuthUserSigningUpв модулеNewsletter. Мы вроде говорим о том, что модули не должны иметь прямых зависимостей от других модулей. При этом листенер изNewsletterпрямо импортирует событие из модуляAuth. Тут бы и дептраку ругнуться самое время.На 5.39 кто-то уже заметил это. И вы отвечаете:
То есть идея модульности была в изолированности модулей друг от друга, а тут мы вдруг можем завязываться напрямую на классы.. Нелогично и ломает всю идею.
А в случае изолированного сервиса как вы себе это представляете? Отдельный сервис
EventsManager, который будет вынужден затащить внутрь себя код со всех остальных модулей, чтобы иметь доступ к классам событий в них определенных?А в этом варианте получается у нас информация об одном событии и его структуре хранится в 100500-ста модулях. Ну ладно название может редко меняться, но а структура данных в json поменяется и нам нужно что? Согласованно в 100500 модулях внести изменение в классы ивентов, или какое-то версионирование изобретать для схемы данных ивента... Выглядит как-то громоздко
Что если вынести события всех модулей в какой-то общий
Comonмодуль, илиEventsилиContracts, который будут все сервисы так или иначе импортировать?Событийная архитектура как раз предполагает, что модули взаимодействуют по событиям. В случае оркестрации события слушает отдельный оркестратор и прямой связи модулей друг с другом нет. Но в случае хореографии сами модули напрямую слушают события друг друга. И в deptrack как раз можно разрешить только хождение за событиями.
Как вы и процитировали, в монолите у нас есть вариант напрямую использовать классы событий и данные для очереди сериализовать и десериализовать прямо в них:
В случае же отдельных микросервисов в очередь сериализуют событие с текстовым именем вроде:
и другие сервисы его десериализуют в свои собственные DTO для каждого интересующего их события.
Верно. В случае микросервисов так и делают. Каждый сервис как отдельный проект в своей документации описывает своё API в виде схем HTTP-запросов и схем событий. И делают версионирование, если хотят что-то поменять.
Любой такой общий пакет Common сразу станет большим и неудобным.
В случае микросервисов нужно учитывать, что разные сервисы могут быть написаны на разных языках программирования. Поэтому использовать имена классов и выносить в пакет и импортировать эти PHP-классы будет бесполезно.
Вместо этого целесообразнее каждому сервису публиковать схемы в неком специальном формате, чтобы потом по ним программисты других сервисов себе автоматически генерировали структуры или классы.
В случае HTTP API можно описать схему в формате OpenAPI для Swagger и по ней через Swagger Codegen генерировать классы для каждого языка программирования. Также можно при необходимости сделать и для событий.
Но если программисты сервиса аккуратно следят за версионированием и обратной совместимостью своих событий, а не переименовывают поля или события наобум, то нам не придётся что-то постоянно согласовывать.
Еще про эти фетчеры для склейки в контроллерах. А относятся ли они к самим модулям или к самому модулю Http? У вас они организованы внутри модулей где-то в папке
Queries.То есть допустим наш фронтенд форму отображает, где список там категорий в дропбокс загрузить надо с какой-нибудь хитрой фильтрацией. Мы пишем
Module\Query\ForThisParticularFormFetcher, кладем его в наш модуль?Сомнение 1: они так разрастаются для каждого кейса в кучу таких фетчеров для каждого клиентского кейса и все в одном месте в модуле?
Сомнение 2: наш чистый модуль с бизнес логикой знает про всякие специфичные для фронтенда юзкейсы. А должен ли он?
Зачем писать
ForThisParticularFormFetcher, если можно написатьCategoryFetcher::all($filter), и использовать его для любого функционала во фронтенде, где нужен список категорий?Они разрастутся независимо от того, в какую папку вы их положите. Хоть в сам модуль, хоть в Http.
Как уже ответили выше, называйте фетчеры не по имени формы, а по тому, какая информация необходима.
На 4.34.43 проверка есть ли активные подписки во внешнем относительно сервиса модуле
Paymentsделается в контроллере сервиса. А хорошо ли так?По идее если подписка отменилась, то мы должны отправить ивент, деактивировать по нему все связанные с подпиской сущности, и никаких дополнительных проверок быть не должно. Экшн должен сразу выдавать без всяких лишних проверок что требуется.
Да, при переходе полностью на событийную работу будет удобнее именно так. При оплате в одном месте активируется доступ в других местах. Тогда внешние проверки не понадобятся.
Вопрос который я обдумываю касается границы между модулями. Всё описанное про модульный монолит с одной стороны делается для более удобной и более изолированной организации кода, что допускает связность до какой-тос тепени. С другой стороны все же это подготовка к тому, чтобы при необходимости в какой-то момент вынести можно было модуль вынести в отдельный сервис.
Но в подходе, что вы описываете, и по ответам в комментариях мы все равно допускаем прямые зависимости (импорт классов) на события внутри модулей, мы вроде как через событийную шину запускаем команды - ок, но с другой стороны у нас в модулях есть набор Queries/Fetchers, которые напрямую импортируются и запускаются внутри слоя с контроллерами и т.д.
Больше того у меня в собственном коде если все мутации реализованы командами и хэндлерами через шину событий, то вот для чтения, я пока что напрямую использую репозитории, а потом напрямую использую модели вытащенные из этих репозиториев, а не какие-то абстрактные фетчеры, массивы, дто. Делаю я так потому что проще, но связности от этого меньше не становится.
Все это наводит на размышления о том, что необходимо будет сделать, чтобы окончательно выделить модуль в серивс? У модуля все равно не хватает четкой границы. Возможно нужен какой-то контракт, который бы был известен HTTP слою (или gateway, или как его еще называют) и по которому он мог бы обращаться к модулю. При этом в случае модульного монолита, конкретная реализация этого контракта дергала бы напрямую нужные
Queryиз модуля. А в случае отдельного сервиса, был бы тот же контракт, но его реализация обращалась бы к модулю через сетевые запросы.Но это все размышления, которые только больше вопросов создают. Например:
Где должен жить этот контракт? Внутри модуля или вне его? Если его напрямую используют какие-то клиенты, то вероятно это все же вне модуля должно быть.
В каком виде? Это класс-интерфейс в случае если у нас всё на одном языке, или какие-то универсальные стандарты описания в случае если нужно интеграцию сервисов на разных языках реализовывать? Про автогенерацию кода пока не знаю ничего
Допустим язык у нас все таки один. А что тогда должно в ходить в подобный контракт? Верооятно интерфейс с набором методов для чтения. В эти методы для чтения мы передаем какие-то параметры допустим в виде Query DTO и получаем результаты в виде какого-то Result DTO. И наверное это тоже часть контракта? Вероятно туда же входят издаваемые события. Возможно даже отправляемые команды тоже часть контракта.
Если это интерфейс, то где должны жить реализации этих интерфейсов? Отдельная от модуля какая-то библиотека-клиент для модуля? При чем один клиент для синхронного обращения к модулю (ну то есть когда вариант модульного монолита), и отдельная для remote-доступа?
Ну тут уже совсем в какие-то дебри мысль уходит.
Потребуется перенести код самого модуля, дописать контроллеры и скопировать к себе классы событий.
Например, код микросервиса комментариев может оказаться таким:
В изначальном проекте, например, оставляем от модуля копии классов Command как есть и оставляем классы Fetcher, переписанные на хождение по сети к сервису.
В случае написания модульного монолита на Java сам язык поддерживает модульность через конструкцию
module. И в модуле можно объявить публичными нужные интерфейсы или классы и только они будут видны снаружи. Это могут быть либо отдельные классы, либо один большой класс-фасад со всеми методами.В языке PHP такого нет. Поэтому приходится договариваться на словах или размечать через deptrack что кому доступно.
Так что в монолите да, можно опираться на публично доступные классы и интерфесы.
Да, это малополезные дебри. Когда надо будет вынести, тогда в монолите за минуту класс
CommentFetcherпереименуете в интерфейс и реализацию вынесете вLocalCommentFetcher. И тогда рядом напишетеRemoteCommentFetcher, где вместо$this->db->query(...)будет$this->http->get(...). Потом переключите класс в конфигурации. И через день удалите старый класс и уже малополезный для одной реализации интерфейс.Если что-то вынесено в отдельный микросервис, то теперь этот микросервис является полноценным отдельным сайтом, с которым теперь из нашего gateway или из любой саги нужно работать по HTTP API и через очередь.
То есть теперь мы со своим микросервисом работаем также, как работаем по API со Сбербанком или другим сервисом. У каждого микросервиса может быть документация с описанием всех JSON-запросов и ответов. Например, если нам нужно на свой сайт загрузить список мероприятий из Яндекс Афиши, то обычно мы в её документации для API находим описание запроса GetEvents и пишем свой класс DTO с нужными нам полями, на который теперь маппим этот ответ. Также можем и с микросервисами.
Изменения в микросервисном проекте происходят не спонтанно. Сначала бэкендеру ставят задачу добавить что-то с новым полем в свой сервис. Он для совместимости это поле добавляет как необязательное или добавляет новую версию запроса по другому адресу. Потом фронтендеру ставят задачу с описанием, какое поле добавили и как его нужно добавить на сайте. Потом бэкендеру могут сказать, что все соседние сервисы обновились и можно это поле делать обязательным. А если кто-то в событие добавил поле с фотографией, то нам для нашего сервиса оно может быть вообще не нужно. Так что следить вручную не так уж и сложно.
Но чтобы не описывать все DTO вручную можем автоматизировать это автогенерацией. Например, при использовании API по протоколу gRPC сервис публикует свои proto-файлы со схемами вроде этих от Tinkoff Invest API. Аналогично с API по протоколу GraphQL сначала в особом формате описывается схема. Также REST API можно описать схему как в примере. И потом другие программисты по этим схемам могут автоматически генерировать все DTO для своего языка и потом через
git diffсмотреть, что там изменилось.Спасибо за содержательные ответы.
Спасибо за стрим! Пока посмотрел первый раз. Поделюсь своей "болью". В наличии интернет-магазин на CMS Prestashop, бэкенд которого не обновлялся 7 лет. За этот срок магазин успел обрасти не только внушительной базой клиентов, но и устаревшими технологиями, ошибками в коде и багами. Такое веб-приложение с трудом выдерживает наплыв клиентов, что не только негативно отражается на лояльности, но и ставит под сомнение безопасность сервиса. Вопрос, с чего начать распил такого монолита на микросервисы, чтобы бизнес не заметил изменений в проекте? Какой сделать первый шаг. Возможности делать проект с нуля нет, только развивать существующий. Спасибо!
Я бы начал с исправления и обновления существующего кода как делал у себя, о чём рассказывал в докладе. А уже потом бы при необходимости постепенно выделял части. Если точно планируете распил на микросервисы, то может помочь книга "От монолита к микросервисам" Сэма Ньюмена. Там как раз про шаги и подходы.
Вот что нашёл в интернете:
Стоит этим заняться?
Можно, но очень осторожно. Rector местами может сломать код. Можно постепенно добавлять ему по одному правилу, запускать и вручную проверять, что ничего не сломалось.
И переводить пошагово по версиям PHP 7.0 → 7.1 → 7.2 → 7.3 → 7.4 → 8.0 → 8.1 → 8.2
стрим огонь, нашел ответы на свои вопросы, спасибо
Добрый день, спасибо за стрим.
Вопрос: Например, есть запрос модуль добавление товара, учитывая что контроллеры лежат не рядом с модулями, а на уровень выше. При добавление товара, сервис принимает только объекты-значение в котором и так проверяются данные.
Что тогда должно проверяться при валидации реквеста или есть смысл от валидации реквеста отказаться?
Для входящего запроса можно оставить только банальные проверки полей вроде NotEmpty и Email, чтобы выводились красивые ошибки вместо Error 500. Если красота не особо нужна, то можно повторно запрос не валидировать, оставив только проверки в объектах-значениях.
Доброго времени всем, Вопрос как быть с долгими скриптами в rabbitmq, server теряет воркера так как php не может ответить на hardbeat во время выполнения скрипта, происходит ределивери, контайнер php-cli получает ошибку, асk не доставляется. У кого какие мысли ?
Если есть возможность, то разбить долгие скрипты на короткие этапы.
тот самый момент когда комментарии ничуть не уступают стриму по своей полезности
Привет!
У меня есть два сервиса:
Form Service — хранит формы.
Comment Service — хранит комментарии к формам.
Оба сервиса имеют свои базы, прямого join на уровне БД нет.
Сейчас я умею:
получать страницы форм (per_page=20)
получать комментарии к этим формам батчами (для каждой страницы)
Но мне нужно сделать страницу, где показываются только формы, у которых есть хотя бы один комментарий, и при этом:
пагинация должна быть корректной (на странице ровно 20 форм);
нужно знать общее количество форм с комментариями для построения пагинации.
Проблема: если просто взять page=1 из Form Service и потом фильтровать формы без комментариев — на странице может быть меньше 20 форм, пагинация ломается.
Вопрос: как правильно реализовать такую пагинацию и подсчёт общего числа форм с комментариями, когда сервисы независимые и join на уровне БД невозможен?
Или войти через: