Практики разделения на модули и микросервисы
На декабрьском стриме мы познакомились с идеями разделения кода на модули или микросервисы и нарисовали такую штуку:
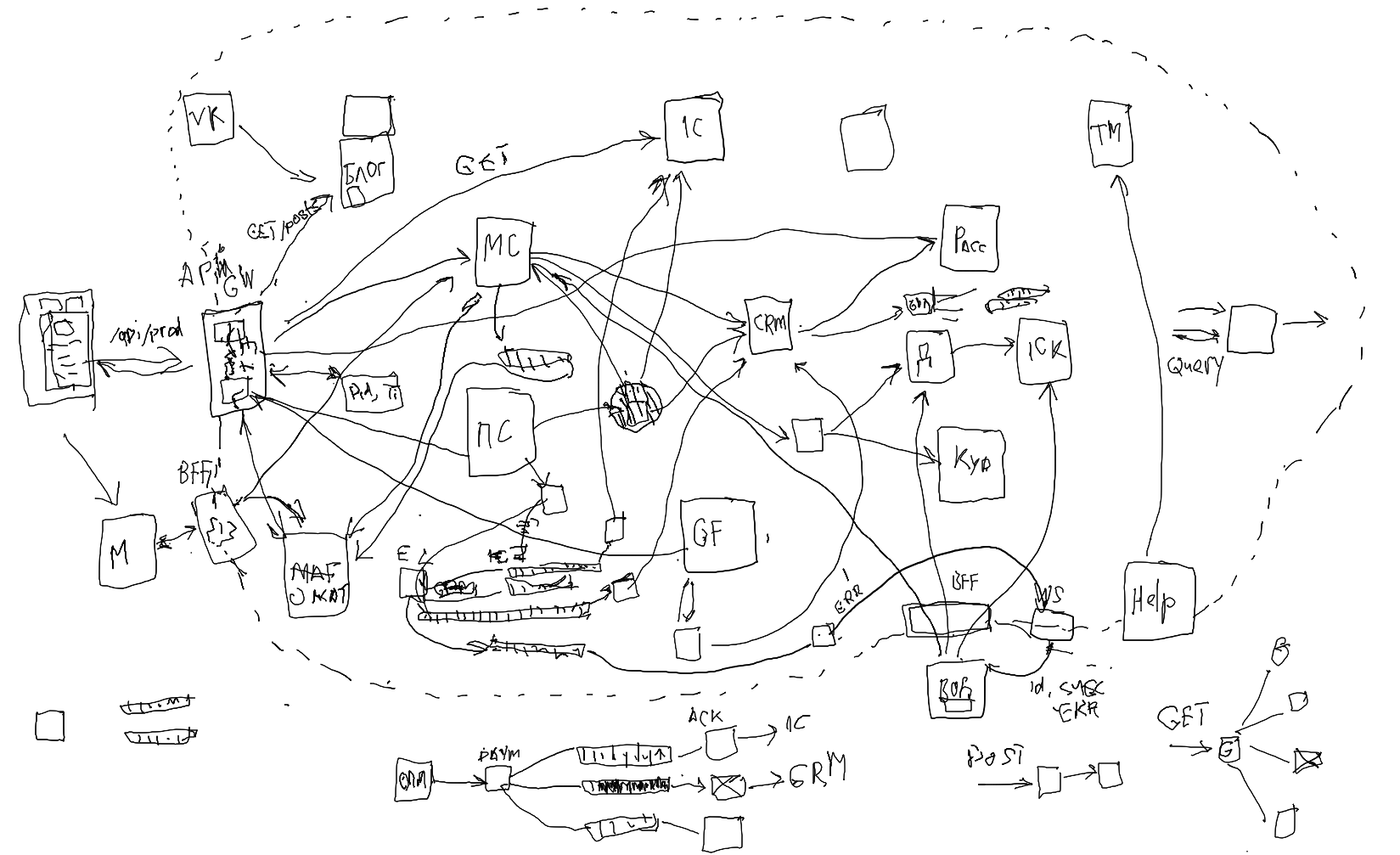
Мы разобрали всё это на своём примере большого магазина, но от вас поступили предложения сделать это и на ваших примерах для ваших предметных областей. Также часто спрашивают о том, как раздробить на модули или микросервисы не новый, а уже имеющийся монолитный проект.
Пришла пора ответить на эти вопросы, спрограммировать работу с очередями, реализовать паттерн Outbox и рассмотреть паттерны и антипаттерны разделения кода на других примерах. И показать практики по разделению уже существующих проектов.
Это мы сделали на новом большом практическом стриме.
В первой части рассказали про принципы с паттернами и реализовали Transactional Outbox для надёжности отправки и доставки событий модулей или микросервисов через RabbitMQ:
- 00:00:00 - Проверка связи
- 00:03:00 - Сервисная архитектура бизнеса
- 00:36:27 - Application Side Joins в контроллере
- 01:03:20 - Если сложная аггрегация данных
- 01:11:00 - Плюсы и минусы разделения
- 01:19:22 - Избыточность данных сторонних сервисов
- 01:26:42 - Надёжность очередей и атомарность операций
- 01:35:47 - Перерыв
- 01:51:28 - Ответы про конкурентность и Kafka
- 02:13:58 - Чем нам полезны SOLID
- 02:39:16 - Распределение ответственностей по GRASP
- 02:56:04 - Для чего придумывали эти принципы
- 03:01:20 - Избавление от связей на чужие классы
- 03:19:32 - Полиморфные связи с разными сущностями
- 03:28:53 - Дублирование или злоупотребления DRY
- 03:46:47 - Чем опасно ссылаться на другую сущность
- 03:55:10 - Перерыв
- 04:11:48 - Ответы на вопросы
- 04:24:18 - Проблемы транзакций в монолите
- 04:36:36 - Саги и Eventual Consistency
- 04:44:15 - Атомарные подоперации и PENDING-статусы
- 04:48:16 - Хореография и оркестрация
- 04:52:12 - Паттерн Transactional Outbox
- 04:58:41 - Программруем очереди и Outbox
- 05:01:08 - Генерация событий в агрегате
- 05:09:15 - Разметка корней агрегатов
- 05:17:19 - Установка библиотеки для AMQP
- 05:20:44 - Установка RabbitMQ в Docker
- 05:28:04 - Добавление модуля рассылки
- 05:36:39 - Подключение к RabbitMQ
- 05:40:14 - Хранилище событий
- 05:43:40 - Автозапись доменных событий в Doctrine ORM
- 05:55:55 - Публикация событий в очереди
- 05:59:50 - Маршрутизация событий по exchange и очередям
- 06:07:24 - Интерфейс Publisher очереди
- 06:09:19 - Публикация сообщений через EventsEmitter
- 06:11:45 - Реализация компонента Queue
- 06:16:25 - История отправленных событий
- 06:24:17 - Ручная доотправка по планировщику
- 06:26:33 - Слушатель рассылки при регистрации пользователя
- 06:29:24 - Подписка слушателей на события
- 06:32:30 - Консольный Consumer
- 06:43:07 - Запуск слушателя в Consumer
- 06:48:01 - Запуск обработчиков в отдельном приложении
- 07:00:30 - Подтверждение обработки
- 07:07:42 - Повторная отправка истории для новых сервисов
- 07:10:56 - Идемпотентность получателя для защиты от повторов
- 07:21:48 - Запуск слушателя в Docker Compose и Swarm
- 07:29:58 - Ожидание установки зависимостей
- 07:34:35 - Отключение событий в фикстурах
- 07:36:43 - Если общий EntityManager
- 07:42:25 - Ответы на вопросы
- 08:06:46 - Что рассмотрим дальше
Во второй части рассказали про разбиение существующих проектов и рассмотрели ваши вопросы:
- 00:00:00 - Проверка связи
- 00:02:23 - О чём сегодня поговорим
- 00:05:43 - Утечки памяти в EntityManager
- 00:11:16 - Подходы к обработке ошибок
- 00:18:17 - Пинг базы данных
- 00:20:58 - Transaction log tailing
- 00:23:58 - Платформонезависимые имена событий
- 00:33:13 - Чтение истории через Polling
- 00:40:09 - Ещё про загрязнение памяти
- 00:42:02 - Параллельное выполнение задач
- 00:56:48 - Другие вопросы
- 00:59:10 - От доменных исключений к событиям в сагах
- 01:16:45 - Игнорирование последовательности слушателей
- 01:20:48 - Потребление пямяти консьюмером
- 01:22:16 - Другие вопросы
- 01:25:40 - Перевод всех ошибок на события
- 01:33:08 - Проблемы от внешних ключей
- 01:46:12 - Другие вопросы
- 01:49:29 - Про поддержку JSON и индексы по выражениям в БД
- 02:08:29 - Связи ORM внутри агрегата
- 02:11:00 - JSON или EAV в БД
- 02:14:40 - Перерыв
- 02:25:06 - Ответы на вопросы
- 02:27:31 - Переупорядочивание шагов для уменьшения откатов
- 02:38:47 - Уход от агрегатов в выборках legacy-проектов
- 02:47:25 - Разбиение по Event Storming или Monolith First
- 02:52:47 - Отпочковывание разросшихся сервисов
- 02:54:08 - От ручной перелинковки до искуственного интеллекта
- 03:22:10 - От поля для видео к сервису для медиафайлов
- 03:37:53 - Паттерн Strangler Fig дробления монолита
- 03:43:47 - Временный Anti-Corruption Layer
- 03:46:40 - Замена кода через Branch By Abstraction
- 03:59:13 - Выном модуля Newsletter в микросервис
- 04:10:50 - Прокидывание JWT-токена аутентификации
- 04:16:46 - Стабильность внешнего API
- 04:22:00 - Упрощение подпроектов при разбиении
- 04:28:06 - Независимые разработка и тестирование микросервиса
- 04:43:08 - Эмуляция зависимостей через Wiremock
- 05:00:08 - Эмуляция клиента и зависимости через Pact
- 05:10:50 - Польза описания схем API
- 05:13:32 - Версионарование внешнего и внутренних API
- 05:21:40 - Логирование и трекинг в распределённых системах
- 05:35:04 - Перерыв
- 05:45:45 - Как тестировать Value Object
- 05:49:15 - Когда использовать Traefik
- 06:02:32 - Вопрос про права доступа в Docker
- 06:16:40 - Как собирать цены в модуле заказа
- 06:28:10 - Кэширование конфигурации в LaminasConfigAggregator
- 06:32:31 - Копировать ли данные из сторонних сервисов
- 06:33:44 - Зависимости от классов других модулей
- 06:46:08 - Избавление от лишних хождений синхронизацией флагов
- 06:50:51 - Нативная модульность в языке или Deptrack
- 07:04:10 - Что если старый проект на CMS
- 07:09:08 - Нужно ли заморачиваться производительностью
- 07:12:45 - Переиспользовать ли Enum-ы
- 07:13:42 - Что если команда сложная с разными вариациями
- 07:15:53 - Формирование кастомных ответов
- 07:19:54 - Независимость от времени создания
- 07:24:41 - Как организзовать запросы между модулями
- 07:26:01 - Внутренние события и интеграционные
- 07:29:28 - Версионарование публичных событий
- 07:30:59 - Риск выполнения групповых операций в обход команд
- 07:39:04 - Нужна ли failure-очередь для ошибок
- 07:43:02 - Ручная публикация без подписки на системный flush
- 07:50:29 - Ответы на вопросы
- 08:08:30 - Всем спасибо!
Оплатить можно самому российской или иностранной картой или попросить работодателя оплатить от имени компании.
Для скидки можете сначала оформить в кабинете безлимитную подписку на наши полезные скринкасты.
А потом или сейчас приобрести записи стрима можно там же в кабинете или здесь:

Супер) Стримы вообще полезная тема. Можно даже попробовать взять чью-то предметную область и собрать участников на доске. И пусть попробуют сами добавлять стикеры)
Подскажите, этот стрим будет доступен в записи для подписчиков? Или именно эту запись нужно будет покупать отдельно?
Да, запись будет доступна всегда.
Отлично! С нетерпением жду выходных, чтоб посмотреть в спокойной обстановке...
Из-за жутких проблем со связью решено провести скоростной интернет и провести эфир в другой день. Заодно подготовлю больше кода с примерами. И можете здесь в комментарии скидывать свои вопросы и примеры, на которые отвечу здесь и разберём на стриме.
О дате стрима сообщу в телеграме и рассылке.
Спасибо за первую часть стрима, может в будущем есть смысл альтернативный интернет иметь под рукой.
Хотелось бы увидеть в следующем стриме код взаимодействия самого сложного кейса из нарисованной схемы декабрьского стрима или может на вашем проекте уже есть что подобное.. может даже показать исполнение с нагрузочными данными как наша спроектированная система будет справляться со всем этим делом
было бы интересно услышать о вашем опыте растаскивания енамов по микросервисам. Когда они лежат внутри модульного монолита ничто не мешает нам перекрестно использовать енамы из разных модулей. Как проблема перечислений решается в микросервисной архитектуре?
Спасибо!
Организация модулей и кода никак не связана с микросервисами. В микросервисах это были бы независимые сервисы со своим независимым кодом и, возможно, на разных машинах. Но если говорим о модульном монолите, то тут вы сами должны контролировать свою архитектуру и её связанность между модулями. Для контроля архитектуры можно использовать deptrack. Кроме того можно создать модуль Shared для общих зависимостей.
Был бы интереснен такой кейс. Например есть заказ с позициями заказа. И в UI есть некоторое количество галочек (checkbox), типа - "Включить заказ в таможенную статистику" или - "Отслеживать кол-во упаковки в заказе" или - "Добавить адрес доставки на карту" т.е. какие-то действия, которые можно сделать с заказом "потом", но которые не являются частью модуля "Заказ".
Т.е. "Включить в таможенную статистику" должен получить позиции заказа, сгруппировать их ТНВЭД коды, и сделать какой-то отчёт для таможни. Т.е. это самостоятельное действие, где позиции заказа являются источником данных.
Тоже самое и "Отслеживать кол-во упаковки" - это действие должно получить информацию о позициях заказа, потом получить информацию как заказ упакован (картон, стекло, аллюминий, пластик) и так же сформировать какие-то данные на этой основе, которые будут например в какой-то определенном отчёте использоваться (например годовой расход такой-то упаковки).
"Добавить адрес доставки на карту" - собственно понятно что делает, но тут вопрос именно в том, что создатель заказа решает, надо его добавлять или нет. И этот флажок тоже не является частью домена "Заказ".
Проставление флажков может быть как через UI в момент создания заказа. Так и с помощью какого-то фонового процесса, который бы вызвал определенную команду CreateOrderCommand модуля заказ.
Вопрос в том, что все эти флажки - не являются частью доменной модели заказа, и их количество неограничено.
Т.е. интересно вот что: - как в UI добавляются эти флажки. Такие бизнес требования могут добавляться с течением времени, и не хотелось бы их хардкодить. Т.е. просто к сущности Заказ можно навешивать какие-то дополнительные действия, где сам заказ является источником данных. Флажки - это для примера банальные checkbox в UI - как передавать эти флажки в команду и как их обрабатывать в command handler - как дать знать тем объектам-обработчикам, что заказ надо ещё так-то и так-то процессировать. Понятно, что можно выкинуть событие OrderCreated, но эти флажки же не являются частью доменной модели "Заказ".
Надеюсь понятно объяснил :)
Спасибо.
Не очень понимаю почему это не может быть частью заказа? К примеру, добавить адрес на карту это дополнительная платная услуга. Которую нужно учитывать и оплачивать. Пример вам заказ тарифного плана у сотового оператора, где можно подключить различное количество дополнительных услуг и опций «безлимит на соцсети» и т д.
Если архитектурный вопрос, то есть два варианта решения:
Добрый вечер.
Вчера Вы сказали, что можно прислать примеры legacy кода для примера. Выслал Вам на почту пару маленьких архивов, приложил текстовые файлы с описанием как работает кода. Надеюсь, что он пригодится на повторном стриме и Вы дадите рекомендации как правильно работать с очередями и rabbitmq.
Добрый вечер. Прошу прощения, что объемно вышло.
1) Сервисный слой возвращает избыточные данные
Условный кейс Сервисный слой возвращает массив dto|entity в контроллер. В response же должны попасть только часть полей. Где лучше разруливать этот процесс, исключая ненужные поля ? 1. В контроллере перед ответом пробегаться по всем dto и формировать из них ассоциативные массивы из нужных полей ? 2. Создать аналогичный класс dto, за исключением ненужных полей. И где то в сервисном слое написать метод, который будет перебрасывать из дто одного типа нужные поля в дто второго типа. А далее контроллер будет сразу отдавать эти дтошки, внутри которых будут только нужные данные 3. Может еще какие то варианты ...
2) Данные из разных модулей сформировать в структуру единого ответа
Условный кейс Есть модуль скиллов. Оттуда мы получаем вложенное дерево дтошек SkillDto. Есть модуль юзеров. Оттуда мы получаем массив дтошек юзеров UserDto. Есть модуль прогресса. Оттуда мы получаем массив дтошек прогрессов ProgressDto. Прогресс имеет связь с одним юзером и одним скиллом.
Для ответа на фронт нам необходимо отдать следующую структуру, как пример [
]
Т.о. нам необходимо создать иерархическую структуру, включающую в себя комбинацию списков сущностей 3 разных модулей.
Какие тут наиболее удобные и наименее болезненные варианты ? 1. Дать одному модулю из 3 (например модулю прогресса) выстраивать эту иерархию ? Отдельно получить массив скиллов, юзеров, закинуть какому-нибудь сервисному классу прогресса в метод эти 2 массива, а он добавит к этому массив прогрессов, сформирует из всех 3 типов данных требуемую структуру и вернет 2. В контроллере отдельно получить массивы скиллов, юзеров, прогрессов, далее прямо в нем же сформировать требуемую иерархию. Из минусов, если требуется эту структуру отдавать не только на этом эндпойнте, но и в других местах, придется дублировать код формирования этой структуры 3. Может еще какие то варианты ...
3) Создание записи в одном модуле требует создание в другом
Условный кейс Есть модуль прогресса. Там есть сущность progress и сущность progress_log. Первое - текущий прогресс. Второе - история изменений прогресса. Есть модуль активности. Там есть сущность activity. Это - активность, выполненная для получения прогресса.
progress имеет связь с одним progress_log. А progress_log имеет связь с одной activity.
Когда создается progress, вместе с ним создаются progress_log и activity. Причем в progress_log необходимо сохранить связь с activity (activity_id), поэтому вначале необходимо создать activity, вернуть ее инкрементный ID и уже потом создать progress_log с этим activity_id. В обратную сторону аналогично, когда создается activity, то вместе с этим создаются progress_log и progress, а в этот progress_log пробрасывается ее ID.
Как тут лучше ? 1. Разруливать все эти процессы и их очередность на уровне контроллера, дергая например сначала создание activity, потом progress_log, потом progress. 2. Разруливать это все на уровне событий и слушателей. Например создаем progress, отправляем событие о создании. На событие вешается обработчик, который создает activity и progress_log (которые правда сущности разных модулей, а создаются одним обработчиком) 3. Может еще какие то варианты ...
4) Обработка событий нужна не во всех случаях Условный кейс. Есть модуль прогресса. Есть модуль активности.
Допустим у нас есть метод создания прогрееса, где мы кидаем событие ProgressCreated. На это событие навешивается слушатель и создает каждому прогрессу активность.
В какой то момент нам становится необходимо в одном из участков логики создавать прогресс без активности. 1. Создавать аналог метода создания прогресса, но который не будет кидать событие ProgressCreated ? 2. Просто убрать с этого события слушателя, который создавал активность и разруливать дальше все создания аткивностей не событийным способом ? 3. Оставить событие и слушателя, но передавать в событие параметр, типа isActivityMustBeCreated ? 4. Может еще какие то варианты ...
Надеюсь примерно понятна суть сложностей. Просьба по возможности затронуть подобные вопросы) Спасибо!
В контроллере. При этом DTO может быть, а может не быть, – тут как захотите. Для контроля структуры можно использовать Psalm. При этом Entity я бы точно не стал использовать. У вас появится куча геттеров, которые нужны для чтения.
Собирать всё на уровне контроллеров с помощью вызовов
QueryHandlerиз разных модулей. Дублирования в этом случае будет условное. К примеру, у вас будет один и тот же Action (Controller) вapi/v2и вapi/v3. Да, они похожи и может казаться, что это дубль. Но это только кажется. В какой-то момент общий сборщик придётся удалить из-за ненужно поля и тогда сервис вовсе потеряет смысл. Кроме того ваши сервисы могут жить на другой машине и общаться по api. Контроллеры и Api Gateway как раз для этого и нужно чтобы соединять всё в одном вместе.Сначала уйти от инкрементного ID. В этом случае он не особо нужен и в будущем будет проще. Но если хотите, то можете оставить и так. Создавайте его сами. В Activity добавьте поля
entity_typeиentity_id. Затем по событиюProgressLogAddedсоздавайте Activity гдеentity_type=progress_log, аentity_id=progress_lig_id.4.Здесь несколько вариантов:
4.1 В прогресс и событие добавьте новое поле, которое будет отвечать за создание активности. После, в модуле активности в подписчике проверяете если это поле true то тогда создаете активность. Минут того, что модуль будет слушать все события, даже те, которые ему не нужны. В результате мы создаём контракт, который мы должны будем поддерживать и версионировать. Например, если захотим поменять название этого же поля, то придётся создать вторую версию этого события, затем ждать когда новый модуль перепишут под новое событие и только тогда можем мигрировать на новую версию события. В монолите это проще, а вот в разных сервисах это сложнее. Особенно если подписчиков на событие много.
4.2 Второй подход заключается в том, что публикуется специальное событие для этого модуля. Например,
ProccessWithAcivityCreated. Тогда нам без разницы что внутри этого события. Нам потребуется только ID прогресса, чтобы создать у себя активность. С выделением отдельного события нам не нужно беспокоиться об изменении полей событияProccessCreated.Что касается нужен ли фабричный метод сложно сказать. Нужно понимать контекст. Скорее всего, в вашем случае, будет достаточно одного создания через конструктор с публикацией второго события по
if($activity ===true)…Как организованы query-запросы между модулями? Чтобы не инжектить хендлеры одних модулей в другие. Прямо сетевыми http-запросами? или через QueryBus и последующий разбор $envelope? или как-то еще?
00:36:27 - Application Side Joins в контроллере Можете через QueryBus, но она должна быть синхронной.
Я имею ввиду, что из себя представляют эти апишки, которые вызываются в указанной части ролика? Вот FavoritesApi - это что? Где этот класс хранится? И если он хранится в вызывающем модуле, то как он связан с модулем Favorites?
FavoritesApi - это пример Http клиента, который написан для сервиса не в монолите или вообще сервис сторонний. Когда ваш код не в монолите, а в разных приложениях они могут взаимодействовать по API. Для них и пишутся такие клиенты. Клиенты можно вынести в отдельную библиотеку, если пользоваться этой библиотекой PHP будете не вы одни. Если вы одни, то можете не выносить в отдельную библиотеку, а положить в своём монолите.
Если у вас модуль Favorites находится в монолите и доступен в этой же кодовой базе - делать для него FavoritesApiClient и обращаться через HTTP не нужно. Просто вызывается Fetcher напрямую или через QueryBus. Тут как Вам угодно.
Это все понятно. Интересует именно вариант модульного монолита . Когда один модуль или какой-то контроллер запрашивает данные из другого модуля. Напрямую пробрасывать квери этого модуля - некомильфо, т.к. в идеале модули не должны зависеть друг от друга. Приходит на ум только квери бас, но это не очень удобно.
Fetcher - это видимо и есть класс, возвращающий результат какого-то запроса? И он лежит внутри модуля, например Favorites. Если, например, админский модуль хочет получить все избранные записи, он обращается к этому фетчеру напрямую?
Верно. Например этот https://github.com/deworkerpro/demo-auction/blob/master/api/src/Auth/Query/FindIdentityById/Fetcher.php.
Обращаться может напрямую, а может через QueryBus, но главное чтобы это было в контроллерах, которые расположены не в модуле
Я Вам отвечаю на вопросы согласно кода Дмитрия: https://github.com/deworkerpro/demo-auction/tree/master/api. Если у Вас так же, то папка HTTP является Api Gateway. Он как раз служит для того, чтобы склеивать информацию с разных модулей и даже сторонних сервисов. Поэтому у вас тут связанности между модулями нет. Api Gateway как дирижёр над вашими модулями. А вот если у вас контроллеры внутри каждого модуля, тогда да. У вас от связанности не уйти в таком случае. Я бы рекомендовал сделать папку Http или ApiGateway, которая как раз и будет связывать данные из ваших модулей. Лично я делаю вместо Fetcher Handler, который работает через QueryBus синхронно. Это позволяет в контроллерах подключать только QueryBus без Handler. Меньше кода и зависимостей. Но вызов всё равно не в модулях, а в Api Gateway
Спасибо за ответ. То, что нужно)
Кстати, репозиторий из трансляции недоступен? В аукционе сейчас вижу только модуль аутентификации и все
Репозиторий, который показывался на стриме - это реальный код сайта deworker.pro. Его не публикуют по понятным причинам. Поэтому код есть только Аукциона. Он тоже со временем приобретёт такой же вид, но позже. Возможно Дмитрий выложит и код сайта deworker.pro, как он сделал это с elisdn.ru (https://github.com/elisdnru/site). Но, думаю, не в ближайшем будущем)
Еще вопросик задам. Предположим мы распилили код на модули и вынесли админку в отдельный модуль. Обычно в админке у нас куча однотипных таблиц, которые могут сортироваться, фильтроваться и содержат агрегированные данные из разных модулей. Как быть в этом случае? Для админки все данные в отдельной бд хранить? Просто сортировка и фильтрация не очень дружат с надергиванием данных из разных модулей и последующим их обьединением.
Стрим доступен всем?
Доступен всем купившим.
по ссылке можно так перейти.
Да, это специфика YouTube.
CommandBusиQueryBus($this->commandBus->dispatch($command)), чтобы в нём уже запускатьValidatorваших DTO. Вместо этого Вы напрямую вызываете$this->validator->validate($command)и$this->handler->handle($command). Из-за этого возникает постоянная необходимость в EventHandler, Action добавлять всегда две зависимости:HandlerиValidator.$user->realizeEvents()можно отказаться от DoctrineSubscriber и сохранять в EventStore события из нашегоFlusher. Для этого Flusher сделать в виде интерфейсаFlusherInterfaceи сделать разные реализацииDoctrineFlusher,EventFlusher,AllFlusherи т д. Теперь избавляемся от подписчика и для прода используемFlusherInterface::class => new AllFlusher([DoctrineFlusher::class, EventFlusher::class]), а для тестовFlusherInterface::class => DoctrineFlusher::class. И в тестах менять ничего не придётся. А так получается очень странно, что мы из-за какого-то доктриновского подписчика будем переписывать все тесты добавляя в каждый тест$user->realizeEvents(). Представим что у нас уже готовый проект и много тестов. Выглядит не очень...aggregeteVersion.По 1 пункту увидел, что в планах перевести на CommandBus. Поэтому можно не отвечать.
Но появился другой вопрос. Какой смысл от «проигрывания» всех прошлых событий, если при любом перемещении или переименования события и слушателя вся система ломается. Например. Переместили подписчик в другое место и идемпотентность уже не работает. Для него это выглядит как новый слушатель. Конечно, вы говорили, что можно использовать свои названия, вместо названий классов, тогда почему это не сделать сразу? Ведь проблема не застанет долго ждать. Либо тогда придётся выдумывать карту алиасов.
Эх, Дмитрий уже не тот. Где фирменное рисование схем символами в ide?
Добрый день! Хочу прояснить, правильно ли понял все по поводу модульного монолита. На проекте выделено три модуля:
Для создания заказа модулю заказов нужны некоторые данные о товарах (для примера не важно какие, дело именно в том, что данные как раз в другом модуле). Для того, чтобы избавиться от связей между модулями делаем так:
Все ли верно ?
Примерно так. API вызывает команду создания заказа, передавая ей список минимальных данных о товарах. И мы рисовали примеры с резервированием и подсчётом цены, как можно эти данныее разложить так, чтобы их из модуля в модуль не передавать.
Вы случайно не про разсетку корней агрегатов ?))
В примере, как описал выше, получается "толстый контроллер". По простому :
А, нашел "Как собирать цены в модуле заказа"
Дмитрий, почему бы вам не попробовать для рисования схем использовать опен сурсный https://excalidraw.com/
Добрый вечер! Подскажите, пжл, почему консюмеров событий не запускать по cron? Встречал на практике, создано в проекте порядка 40 разных очередей и такое же количество консюмеров запускается по cron при этом количество воркеров настраивалось командой sleep, и вроде живут. В чем особенность такого подхода?
Если это просто запуск одноразовой обработки вроде
queue:handleчерез Cron вместо запуска многоразовогоqueue:listenчерез супервизор, то это не даёт ничего полезного. Только лишний раз нагружает систему постоянными перезапусками и подключениями скриптов-консьюмеров каждую секунду или другой интервал из sleep. Если на 40 очередей попробуют так запускать 400 скриптов раз в секунду или чаще, то это сильно нагрузит систему.При классическом подходе консьюмер запускается и подключается один раз и навсегда (или пока не перезапустится системой при какой-нибудь ошибке) и молча ждёт сообщений из очереди. И так могут быть запущены хоть 400 скриптов. Лишние будут просто стоять без движения. Ну и сообщение из соединения скрипт получает практически мгновенно, а не когда в следующий раз запустится по Cron-у.
Добрый день, возникает проблема при запуске консьюмера, на обработку каждого сообщения создается новое подключение и канал. Если у вас много сообщений в очереди, то это становится большой проблемой. PHP-DI контейнер создает каждый раз новый экземпляр AMQPStreamConnection и каждый вызов $connection->channel() создает новый канал.
Добрый день, начал смотреть ваш стрим и вы говорите что нужно не делать join, а также не должно быть связей между модулями, к примеру как быть в такой ситуации, есть модуль dashboard, User и модуль Currencies, нужно в дешборде вывести информацию о пользователе, список всех его валют, все валюты конвертировать к usd, как быть если все между собой связано?
Или войти через: